Por default, o Django cria chaves primárias do tipo inteiro (32 bits) quando usado com o banco PostgreSQL. Estes campos são incrementados automaticamente e funcionam perfeitamente bem em ambiente local. Um problema que aparece quando você cria uma API é o fato de seus ids sequenciais e numéricos exporem detalhes de sua base de dados.
Imagine que seu cliente tem o id 1, ele pode imaginar (e com razão) que é seu primeiro cliente. O mesmo pode ser utilizado por concorrentes para saber quantos novos clientes você obteve em determinado período, bastando para isso criar uma nova conta. Isto pode gerar uma vontade incontrolável em algumas pessoas de explorar os valores de suas chaves. Com chaves inteiras, esta tarefa é fácil, basta incrementar o valor da chave de 1 e tentar novamente.
Uma alternativa às chaves inteiras é a utilização de UUID, geradas aleatoriamente, porém maiores (128 bits). Por serem 4 vezes maiores, já podemos imaginar que o espaço em disco ocupado pelas chaves e índices vai também aumentar. Mas e quanto as operações de inserção, busca e atualização de tabelas? Quanto custa substituir as chaves inteiras por UUIDs.
Exemplo de UUID:
cab5ade3-2dc3-4344-b5a6-80df59f91458
Eu resolvi fazer um teste, comparando chaves inteiras, uuids e uma solução mista, onde a uuid é utilizada fora da aplicação, mas mantendo uma chave primária inteira.
Os modelos são bem simples (chaves inteiras, modelo de referência):
class A(models.Model):
bigtext = models.TextField()
name = models.CharField(max_length=100)
counter = models.IntegerField(default=0)
class B(models.Model):
parent = models.ForeignKey(A, related_name="bs")
bigtext = models.TextField()
counter = models.IntegerField(default=0)
class C(models.Model):
parent = models.ForeignKey(B, related_name="cs")
grandparent = models.ForeignKey(A, related_name="cs")
bigtext = models.TextField()
counter = models.IntegerField(default=0)
A, B, C e foram configuradas de forma a estabeler um relacionamento entre elas.
Vamos modificar os modelos para utilizarmos UUIDs:
class A(models.Model):
id = models.UUIDField(primary_key=True, default=uuid.uuid4, editable=False)
bigtext = models.TextField()
name = models.CharField(max_length=100)
counter = models.IntegerField(default=0)
class B(models.Model):
id = models.UUIDField(primary_key=True, default=uuid.uuid4, editable=False)
parent = models.ForeignKey(A, related_name="bs")
bigtext = models.TextField()
counter = models.IntegerField(default=0)
class C(models.Model):
id = models.UUIDField(primary_key=True, default=uuid.uuid4, editable=False)
parent = models.ForeignKey(B, related_name="cs")
grandparent = models.ForeignKey(A, related_name="cs")
bigtext = models.TextField()
counter = models.IntegerField(default=0)
E uma solução híbrida alternativa, com duas chaves, uma uuid e outra inteira:
class A(models.Model):
surrogate_id = models.UUIDField(default=uuid.uuid4, editable=False, unique=True)
bigtext = models.TextField()
name = models.CharField(max_length=100)
counter = models.IntegerField(default=0)
class B(models.Model):
surrogate_id = models.UUIDField(default=uuid.uuid4, editable=False, unique=True)
parent = models.ForeignKey(A, related_name="bs")
bigtext = models.TextField()
counter = models.IntegerField(default=0)
class C(models.Model):
surrogate_id = models.UUIDField(default=uuid.uuid4, editable=False, unique=True)
parent = models.ForeignKey(B, related_name="cs")
grandparent = models.ForeignKey(A, related_name="cs")
bigtext = models.TextField()
counter = models.IntegerField(default=0)
O programa completo pode ser baixado aqui: https://github.com/lskbr/keyperftest
Ambiente de testes:
Processador: Intel Core i7 4790K 4 GHz
Disco: Samsung SSD 850 EVO
Ubuntu 16.04 rodando em VM VirtualBox (4 GB, 4 CPUs)
PostgreSQL 9.5.2 rodando via docker
Django 1.9.6
Python 3.5.1
Testes realizados em: 28/05/2016
Rodando o programa com 1000 registros, obtemos os seguintes resultados (todos os tempos em segundos):

Neste primeiro resultado, percebemos o tempo de inserção com chave inteira e uuid não é muito diferente. A solução mista (chave inteira + uuid) leva mais tempo.

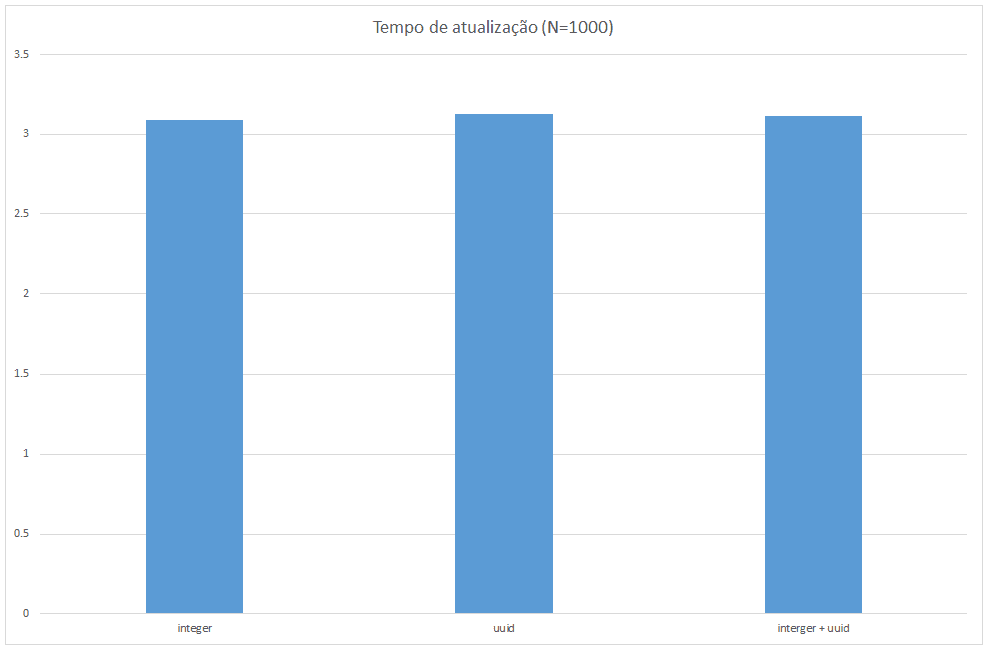
E nesta imagem o resultado das operações de atualização da tabelas. No caso, atualizamos a partir de C, as tabelas A e B. Mais uma vez as chaves inteiras tiveram um melhor desempenho e a combinação de chave inteira com uuid se apresenta como uma meio termo.
Repetindo os testes, mas desta vez para 10.000 registros, as diferenças se tornam mais claras.

Acesso:

Atualização

Embora haja diferença entre os tempos destas operações, os resultados não demonstram uma lentidão excessiva ao aumentarmos o tamanho da chave 4 vezes, de 32 para 128 bits.
Considerando os tempos das operações com chaves inteiras como 100%, temos os seguintes resultados médios:
| Inserção | Atualização | Acesso | |
| integer | 100.00% | 100.00% | 100.00% |
| uuid | 101.64% | 108.77% | 108.97% |
| interger + uuid | 106.15% | 106.63% | 111.85% |
Utilizar as UUIDs em URLs também aumenta o tamanho das strings, mas acredito ser um preço a se pagar pela comodidade.
Além de esconder a sequência de chaves e não possibilitar a dedução do número de registros de seu banco de dados, UUID possuem as seguintes vantagens:
a) Podem ser geradas em várias máquinas, permitindo que seu banco rode em vários servidores sincronizados.
b) Evitam ataques por dedução das chaves
Desvantagens de UUIDs:
a) Ocupam mais espaço em disco e em memória (128 bits)
b) São um pouco mais lentas para gerar
c) Aumentam o tamanho das URLs
d) São difíceis de memorizar (o que pode dificultar as tarefas de depuração)
Eu decidi utilizar UUID em projetos futuros, uma vez que a segurança das chaves é mais importante para mim que o espaço ocupado por estas e que não há uma degradação importante na velocidade de acesso ao banco. O uso de UUIDs também facilitar a utilização do banco em clusters e até mesmo a geração de chaves offline.
2 comentários:
Parece que você fez esse teste sob encomenda pra mim :) Eu estava discutindo isso com minha equipe nessa semana :)
Gostaríamos de usar UUIDs mas a gente tinha medo de degradar performance... iríamos testar isso nos próximos dias :)
Muito bom o artigo. Obrigado por compartilhar!
Postar um comentário